How to Break Any AI Model (A Machine Learning Security Crash Course)


You've probably heard AI is taking over the world - but here's the dirty little secret: most AI models are shockingly fragile. I'm talking 'one pixel change breaks everything' fragile.
Today we'll cover what AI actually is, how machine learning works, and then I'll show you the fundamental attacks that can break almost any AI system. Whether it's image recognition, spam filters, or self-driving cars - they all share the same vulnerabilities. Let's get into it.
AI vs ML - WHAT'S THE DIFFERENCE?
First thing's first: AI and Machine Learning are not the same thing, even though everyone uses them interchangeably. Artificial Intelligence is the broad goal - making computers do things that normally require human intelligence. That includes everything from your chess-playing computer to Siri to actual sci-fi robots.
Machine Learning is a specific approach to AI. Instead of programming explicit rules, you feed a system tons of examples and let it figure out the patterns. It's the difference between 'here are 10,000 if-statements for detecting cats' versus 'here are 10,000 pictures of cats, figure it out yourself.'
Think of it this way: AI is the destination, ML is the vehicle. And as we'll see, that vehicle has some serious safety recalls. The key insight is that ML models learn from data, which means they're only as good as that data. And that creates our first major vulnerability - but we'll get to that later.
TYPES OF ML - LEARNING PARADIGMS
There are three main ways machines learn, and understanding this is crucial to understanding how they break.
First up: Supervised Learning. This is the teacher-student model. You give the AI labeled examples - 'this is a cat, this is a dog, this is a very confused raccoon.' The model learns to map inputs to outputs. Most of the AI you interact with daily uses this: image recognition, spam detection, voice assistants.
Second: Unsupervised Learning. No labels, no teacher. You dump data on the model and say 'find patterns.' It might cluster similar items together or detect anomalies. Think customer segmentation or fraud detection systems that flag 'weird' transactions.
Third: Reinforcement Learning. This is trial and error on steroids. The model tries actions, gets rewards or penalties, and learns what works. This is how DeepMind's AlphaGo beat world champions and how Boston Dynamics' robots learned to do parkour.
Here's the security angle: each paradigm has different attack surfaces. Supervised learning? Poison the training labels. Unsupervised? Manipulate what counts as 'normal.' Reinforcement? Exploit the reward function. It's a hacker buffet.
For this post, we'll focus mostly on supervised learning since that's what most production AI systems use...not counting LLMs which is totally separate can of worms.
TYPES OF ML PROBLEMS
Now let's talk about what ML models actually do. There are several main problem types:
Classification: Put things into categories. Is this email spam? Is this tumor malignant? Is this person wearing a mask? It's multiple choice questions for computers.
Detection: Find and locate objects. Where are the pedestrians in this image? Where's the suspicious network traffic? It's classification plus location.
Regression: Predict continuous values. What will the stock price be? How many ice creams will we sell tomorrow? What's this house worth? It's fill-in-the-blank with numbers.
Segmentation: Label every pixel or part. Which pixels are road, which are sidewalk, which are that guy about to step in front of your self-driving car? Critical for medical imaging and autonomous systems.
Generation: Create new content. This is your DALL-E, Stable Diffusion, and LLM territory. Generate images, text, music, deepfakes - you name it.
Each of these has different security implications. A misclassified email is annoying. A misclassified stop sign? That's a safety critical failure. The stakes vary wildly, but the underlying vulnerabilities are surprisingly similar.
DECISION BOUNDARIES - THE KEY TO EVERYTHING
Alright, here's where it gets interesting. At the heart of every ML model is something called a decision boundary. Imagine you're plotting data on a graph. Cats on one side, dogs on the other. The decision boundary is the line - or in higher dimensions, a hyperplane - that separates them. Everything on this side is a cat, everything on that side is a dog.
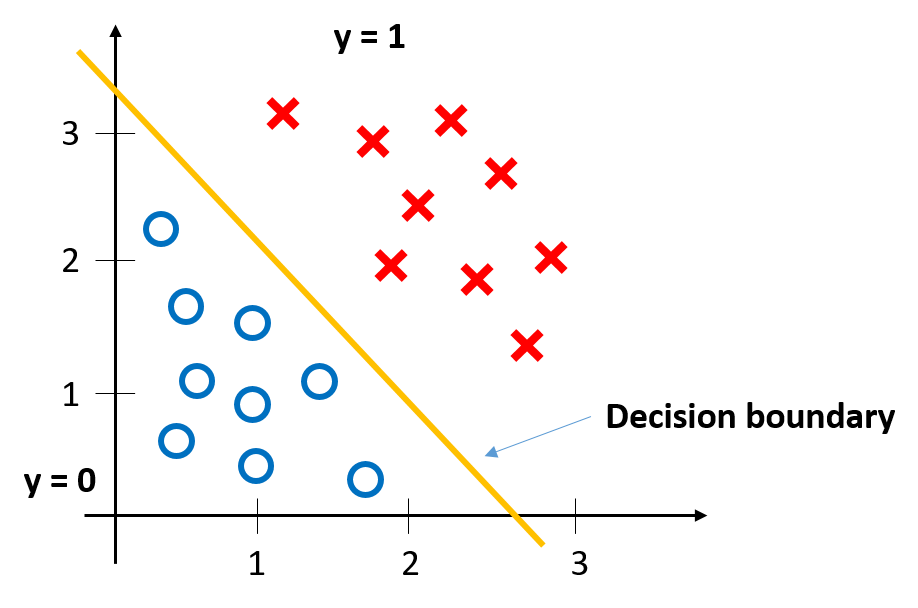
Here's the math, keeping it simple. For a linear boundary:
\[ f(x) = w · x + b \]
Where 'w' is a weight vector, 'x' is your input, and 'b' is a bias term. If f(x) is positive, it's a cat. Negative? Dog. That's the decision.
In reality, these boundaries can be incredibly complex. Neural networks create twisted, folded, high-dimensional boundaries that can separate things like 'pictures of cats wearing hats' from 'pictures of cats not wearing hats.' The boundary might have thousands or millions of dimensions.
Here's the critical insight: the model only learned where to draw the boundary based on the training data it saw. It has NO idea what's really a cat or a dog. It just knows 'this side of my weird mathematical surface means cat, that side means dog.'
This is why decision boundaries are everything in ML security. If you can manipulate input to cross that boundary, you can make the model output anything you want. And as it turns out, for a lot of models, that's disturbingly easy.
WHY DECISION BOUNDARIES MATTER FOR SECURITY
So why should security professionals care about decision boundaries? Three reasons:
First: Brittleness. These boundaries are razor-thin in high-dimensional space. A tiny change - we're talking modifications invisible to the human eye - can push an input across the boundary. Your model goes from 99.9% confident it's a cat to 99.9% confident it's a guacamole recipe. I'm not even kidding.
Second: Exploitation Surface. Attackers don't need to understand your entire model. They just need to find the boundary and figure out how to cross it. It's like not needing to understand all of airport security - you just need to find the one weak point.
Third: No Ground Truth. The model has no concept of what things 'really are.' It only knows the mathematical boundary. There's no sanity check, no 'wait, this still looks exactly like a stop sign' verification. If you cross the boundary, you win.
This is fundamentally different from traditional software security. There's no buffer to overflow, no SQL to inject. You're exploiting the mathematical space itself. You're quite literally hacking geometry.
ATTACK #1 - ADVERSARIAL EXAMPLES
Attack number one: Adversarial Examples. This is the classic ML attack, and it's beautiful in a terrifying way.
The idea: add carefully crafted noise to an input that's imperceptible to humans but completely fools the model. Here's the math behind it:
\[ x_{adv} = x + ε · sign(∇_x L(θ, x, y)) \]
Don't panic. 'x' is your original input, 'ε' (epsilon) is a tiny step size, and the gradient tells you which direction to nudge pixels to maximize the model's error. You're essentially asking 'which way should I push to make the model most confused?'
Real examples: researchers added stickers to stop signs that made Tesla's Autopilot see speed limit signs [1]. They put specific patterns on glasses that made facial recognition see them as someone else. They modified images by changing literally ONE pixel and broke classification.
The scary part? These attacks transfer. An adversarial example crafted for one model often works on completely different models. It's like finding a master key that opens multiple locks.
Defenses include adversarial training, where you train on attacked examples, gradient masking, and input sanitization. But honestly, it's an arms race. For every defense, there's a new attack variant.
ATTACK #2 - DATA POISONING
Attack number two: Data Poisoning. This is the long con of ML attacks.
Remember how ML models learn from training data? What if an attacker can sneak malicious examples into that data? They can create backdoors that persist after training.
Classic example: the BadNets attack [2]. Researchers trained a face recognition system where any face with a specific pair of glasses would be classified as a particular person. The trigger was subtle, the backdoor was permanent.
Or consider this: Microsoft's Tay chatbot [3] lasted about 16 hours before Twitter users poisoned it with toxic data and it started spewing hate speech. That's data poisoning in real-time.
The math is deceptively simple. If you control even a small percentage of training data - sometimes as little as 3% - you can significantly influence the learned decision boundary:
\[L_{poisoned} = L_{clean} + λL_{backdoor} \]
You're optimizing for both normal accuracy and your backdoor trigger.
Defense requires strict data validation, anomaly detection during training, and provenance tracking. But if you're training on web-scraped data or user-generated content, you're playing with fire.
ATTACK #3 - MODEL INVERSION & EXTRACTION
Let's rapid-fire through two more attacks.
Model Inversion: This is reconstructing training data from the model. Researchers have extracted faces from facial recognition systems, medical records from health prediction models, and personally identifiable information from language models. If your model memorized sensitive data, attackers can get it back out.
The attack queries the model strategically and uses the confidence scores to reconstruct inputs:
\[ x* = argmax_x P(x|y, θ) \]
You're basically asking 'what input would give me this output?' and working backwards.
Model Extraction: We covered this briefly in my LLM post. Query a model enough times, record inputs and outputs, train your own copy. Steal the decision boundary without stealing the actual model weights.
Both attacks exploit the fact that models leak information through their outputs. Even aggregate predictions can reveal individual training samples.
Defenses: differential privacy adds noise to outputs to prevent reconstruction, query limiting and rate throttling slow down extraction, and output rounding reduces precision. But there's always a trade-off between utility and security.
## PART 9: GENERAL DEFENSE STRATEGIES (9:00-9:45)
So how do you actually defend against all this? Here's your ML security playbook:
One: Defense in Depth. Don't rely on the model alone. Add input validation, output sanity checks, and monitoring. If your model suddenly thinks every image is a cat, something's wrong.
Two: Adversarial Training. Train on attacked examples. It's like vaccination - expose the model to weakened attacks so it builds resistance. It doesn't solve everything, but it helps.
Three: Ensemble Methods. Use multiple models with different architectures. An attack that works on one might fail on others. Democracy for AI.
Four: Certified Defenses. Some techniques can mathematically prove robustness within certain bounds. They're expensive and limited, but for critical systems, they're worth it.
Five: Monitoring and Anomaly Detection. Watch for unusual input patterns, confidence score distributions, and query behaviors. Attacks often have statistical fingerprints.
Six: Principle of Least Privilege. Don't give your model more power than it needs. If it only needs to classify cats and dogs, don't let it access your database.
The key insight: treat ML models as untrusted components. They will fail. They will be attacked. Design your system accordingly.
CONCLUSION
So there you have it: Machine learning is about finding decision boundaries in high-dimensional space. Those boundaries are fragile, exploitable, and fundamentally different from traditional software.
Adversarial examples cross the boundary with imperceptible changes. Data poisoning corrupts the boundary at training time. Model inversion and extraction leak information through the boundary. Each attack exploits the fact that ML models don't truly understand anything - they just know which side of a mathematical surface an input falls on.
As we deploy AI in increasingly critical systems - medical diagnosis, autonomous vehicles, financial trading, security systems - we need to take these vulnerabilities seriously. Adversarial training, ensemble methods, monitoring, and defense in depth aren't optional. They're requirements.
The field of AI security is still young, and attackers are creative. But by understanding these fundamental concepts, you're better equipped to build robust systems or assess the risks of existing ones.
Thanks for reading, and if you found this helpful, subscribe for more machine learning and security content. Until next time, stay safe and happy learning.
RESOURCES
Foundational Papers:
-
"Explaining and Harnessing Adversarial Examples" - Ian Goodfellow et al. (2014)
- The seminal paper introducing the Fast Gradient Sign Method (FGSM)
- https://arxiv.org/abs/1412.6572
-
"Intriguing Properties of Neural Networks" - Szegedy et al. (2013)
- First major work on adversarial examples in neural networks
- https://arxiv.org/abs/1312.6199
-
"BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain" - Gu et al. (2017)
- Comprehensive look at backdoor attacks via data poisoning
- https://arxiv.org/abs/1708.06733
-
"Model Inversion Attacks that Exploit Confidence Information" - Fredrikson et al. (2015)
- Key research on extracting training data from models
- https://www.cs.cmu.edu/~mfredrik/papers/fjr2015ccs.pdf
-
"Stealing Machine Learning Models via Prediction APIs" - Tramèr et al. (2016)
- Foundational work on model extraction attacks
- https://arxiv.org/abs/1609.02943
Security Frameworks & Guidelines:
-
OWASP Machine Learning Security Top 10
- https://mltop10.info/
- Comprehensive list of ML security risks with mitigation strategies
-
MITRE ATLAS (Adversarial Threat Landscape for AI Systems)
- https://atlas.mitre.org/
- Knowledge base of adversary tactics and techniques for ML systems
-
NIST AI Risk Management Framework
- https://www.nist.gov/itl/ai-risk-management-framework
- Guidance for managing AI risks in production systems
-
Microsoft Responsible AI Standard
- https://www.microsoft.com/en-us/ai/responsible-ai
- Best practices for building secure and trustworthy AI
Tools & Libraries:
-
Adversarial Robustness Toolbox (ART)
- https://github.com/Trusted-AI/adversarial-robustness-toolbox
- Python library for adversarial attack and defense research
-
CleverHans
- https://github.com/cleverhans-lab/cleverhans
- Library for benchmarking ML systems' vulnerability to adversarial examples
Real-World Case Studies:
-
"Robust Physical-World Attacks on Deep Learning Visual Classification" - Eykholt et al.
- The stop sign attack on autonomous vehicles
- https://arxiv.org/abs/1707.08945
-
"Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition" - Sharif et al.
- Adversarial glasses for fooling facial recognition
- https://www.cs.cmu.edu/~sbhagava/papers/face-rec-ccs16.pdf
-
Microsoft Tay Incident Analysis
- Real-world data poisoning attack on a chatbot
- https://blogs.microsoft.com/blog/2016/03/25/learning-tays-introduction/
Datasets for Testing:
-
ImageNet-A (Natural Adversarial Examples)
- https://github.com/hendrycks/natural-adv-examples
- Dataset of naturally occurring adversarial examples
-
CIFAR-10-C (Corrupted CIFAR-10)
- https://zenodo.org/record/2535967
- Robustness benchmark with common corruptions
Communities & Conferences:
-
r/MachineLearning (Reddit)
- Active discussions on ML security
-
AI Village (DEF CON)
- https://aivillage.org/
- Community focused on AI security research
-
Key Conferences:
- NeurIPS (Neural Information Processing Systems)
- ICML (International Conference on Machine Learning)
- CVPR (Computer Vision and Pattern Recognition)
- USENIX Security Symposium
- IEEE Security & Privacy (S&P)


